
Synthetic Aperture Radar (SAR) Systems for lightweight UAVs enabled by rugged GP-GPUs
StoryJuly 03, 2012

William Pilaud
Curtiss-Wright
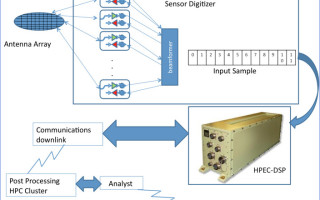
Manned and unmanned aircraft system designers use Synthetic Aperture Radar (SAR) to map and image terrain. SAR can also function as a surveillance device to track and identify moving objects. SAR technology has great potential for use in Unmanned Aerial Vehicles (UAVs) but the amount and size of the super-computer level of processing needed to obtain high resolution actionable data has limited the altitude and speed at which aircraft can effectively use SAR for terrain mapping. As a consequence, RADAR data from a high-speed data link must be post-processed by a large cluster of computers on the ground, resulting in non-real-time delivery of imagery and actionable intelligence to the warfighter.
The great potential of lightweight SARs in small UAVs has been hampered by Size, Weight, and Power (SWaP) constraints associated with previous generations of silicon technologies. Now, SAR can be deployed using High Performance Embedded Computing (HPEC) architectures based on advanced COTS General Purpose Graphic Processor Unit (GP-GPU) processors such as NVIDIA’s Fermi architecture devices, with sophisticated ruggedization and thermal management packaging techniques. These new HPEC architectures eliminate earlier performance and thermal management hurdles to enable optimal use of SAR technology on UAVs. GP-GPUs, with their large number of cores, floating math functionality, and impressive computational performance, will ease and speed the integration of SAR technology into today’s smaller UAVs with real-time actionable data to the warfighter. By tweaking the architecture of the system, rugged COTS GP-GPUs can potentially improve the processing capability of traditional SAR systems by a factor of four to 80 times.

Figure 1: SAR system
SAR enables an aircraft’s RADAR to function as a very large array by combining the terrain images the system scans and captures. This technique effectively uses the aircraft’s motion to widen the RADAR aperture. SAR topological images require massive amounts of processing capabilities delivered by supercomputing computational systems. The problem is that, until now, use of SAR surveillance in aircraft has limited the aircraft’s speed. This has been especially true for cases where the desired data is critical and intended for real-time action.
Deploying supercomputer capabilities onboard aircraft, particularly space and weight constrained UAVs, demands a balance of SWaP, system capabilities, and the timeliness of actionable intelligence. The key factors that enable or limit the actionable real-time use of SAR data are field-of-view, loss of data or resolution, and delayed awareness of an event. The ability to optimize SAR performance for real-time use is directly proportional to the compute power available. In UAVs SAR is typically deployed on SWaP- optimized HPEC clusters comprising rugged processors interconnected with low-latency, high speed and high bandwidth networks.

Figure 2: SAR block diagram
While the method of how RADAR data is transformed into an image is beyond the scope of this paper, a description of one aspect of a SAR algorithm helps to explain how GP-GPUs can improve SAR performance. A critical part of a SAR algorithm consists of three main stages: FDC (Frequency Domain Convolution) in the row dimension, corner turn, and FDC in the column dimension.

Figure 3: Corner Turn
The traditional technique for performing this SAR algorithm is to stream data to an HPEC system. The system is architected to segment the HPEC systems such that a set of processors is responsible for computing the FDC of a row, or rows, of the sensor data. The computed result of the row FDC data is then sent to a next set of processors, using a corner turn (rows of the data set become columnar), which then processes the FDC of the column(s).

Figure 4: Traditional HPEC SAR
In some instances, the FDC will largely consist of Fast-Fourier Transforms (FFTs). FFTs are a function of moving data from memory to the processor, performing a calculation, and then sending that result to memory for use on yet another subsequent calculation. This means that, in essence, the performance of the SAR algorithm is directly dependent on an optimization of data movement.
In SAR systems, algorithms are typically divided into inner and outer loops. With inner loops, data is processed in processor memory (cache or DRAM memory). With outer loops data is transferred to other processors. The algorithm’s latency is minimized by sending most data transfers to the fastest available memory. Therefore, keeping the data persistent or closer to the processor results in optimal performance (or lower latency) because data movement is faster in cache versus DRAM or fabric networks. The obvious strategy for improving SAR algorithm performance is to spread as many sets as possible of the row FDC data and column FDC data over multiple processors.
Minimizing the amount of data processed on one processor improves the latency of the system, but the downside is that this increases the stress on the outer loop or the network fabric inter-connecting the processors. SWaP constraints, limiting the size and weight of a deployable SAR system, have led to compromises between the number of processors and the fabric capability. Unfortunately, improving overall system performance isn’t as simple as just increasing processor performance. That’s because for these types of I/O (input and output) bound applications the performance of the network fabric can become a bottleneck and thus a key performance limiter. What’s needed are HPEC systems that optimally combine higher speeds for lower latency processing and higher bandwidth fabric networks that are able to keep up with the higher speed processors’ capabilities.
SAR and air speed
Again, a critical hurdle for lightweight SAR performance has been the direct correlation between system performance and the aircraft speed. The SAR uses the motion of the aircraft to help “image” the terrain. It can detect reflections from the beam and then “add” these reflections together to form a composite image. The speed of the SAR system’s DSP determines how fast the aircraft can fly over the desired terrain. If the DSP is too slow the aircraft must reduce its speed so it can properly image the object. Air speeds that outstrip the ability of the DSP will result in lost, potentially critical, image data.
A GP-GPU is one of the highest speed processors available. They feature hundreds of cores connected to a high-speed DRAM. Creating a traditional SAR system with GP-GPUs might appear to simply be an exercise of selecting the right network fabric to use to stream the data effectively over multiple clusters of GP-GPUs. However, even the fastest embedded networks, such as 10 Gigabit Ethernet and 20 Gigabit/per second RapidIO would be incapable of keeping up with the performance benefits provided by the GP-GPUs.
Therefore, a way to significantly increase the speed of a SAR DSP is to design it so that a complete frame of SAR sensor data can fit into the GP-GPU memory. This would make it possible to replace that part of an HPEC system that computes the FDC with a single GP-GPU. In effect, the GP-GPU functions as an HPEC system on a chip. By extension, this now makes the performance of the GP-GPU FDC computation dictate the possible effective aircraft speed. For example, a SAR RADAR transmitting 20 megabytes per second of sensor data would need 100 seconds to fill the GP-GPU memory. Some of the new NVIDIA Fermi Architecture-based GP-GPUs can achieve a peak performance of 432 Gigaflops (or 432 billion floating point operations - GFLOPS). This means that in 100 seconds the GP-GPU would be capable of more than 40 trillion floating point operations -TFLOPs. With this GP-GPU performance capability, FDC and other computationally demanding algorithms, such as change detection, GMTI, interleaving SAR and GMTI, and real-time image compression, become achievable using COTS-based HPEC systems in small lightweight SARs.

Figure 5: GP-GPU Architecture (HPEC on a board)
Furthermore, if the SAR data is distributed to a cluster of GP-GPUs the aircraft speed will be dictated by the processing speed and/or number of GP-GPUs in the cluster. For example, if a cluster comprising ten (10) GP-GPUs is confronted with that same 20 megabytes per second of sensor data, a single GP-GPU in the cluster can deliver 3 million TFLOPS of performance.
GP-GPUs also provide a significant advantage when handling data movement, which is typically the greatest determining factor in SAR algorithm performance. A GP-GPU’s memory interface can provide data rates as fast as 80 gigabytes per second (GB/s) with an 8 GB/s PCI-Express I/O. Compared to traditional CPU memory controller, data movement using a GP-GPU is 4x faster, and when compared to fabric speeds data movement with GP-GPUs is 80x faster. Because SAR algorithms are bound to data movement speed, it follows that GP-GPU-based SARS processing can be 4x to 10x faster than traditional processor based HPEC systems. This significant increase in processing performance will enable aircraft to fly faster and higher, delivering more imaging capability without any reduction in the quality of image resolution provided by traditional CPU-based HPEC SAR systems.

Figure 6: Scaled GP-GPU system.
The next step is to take a GP-GPU-based HPEC system and test it in real world applications. In aircraft with “human friendly” environments, where the cabin is pressurized and there is minimal shock and vibration, and there are no restrictive MTBF requirements, a desktop PC-type system may suffice. For applications deployed in harsh environments, such as unpressurized, high-vibration conditions, a rugged COTS GP-GPU module such as Curtiss Wright Controls Defense Solutions’ (CWCDS) 6U OpenVPX (VITA 46/65) VPX6-490 GP-GPU board should be considered. When combined with a companion SBC, such as the CWCDS VPX6-1956 or CHAMP-AV8, the VPX6-490 delivers one Teraflop peak processing performance. Each of the VPX6-490’s NVIDIA Fermi based GP-GPUs has 2 Gigabytes of GDDR3 memory with over 80 GB/s bandwidth. The board set comes in a variety of cooling architectures including air-cooled and extended temperature air-cooled, but is also available in more extreme ruggedization packaging such as conduction cooled or air-flow through (AFT).
A complete supercomputer level HPEC system can be built by integrating 4 (four) sets of VPX6-490/VPX6-1956 or CHAMP AV8 cards (eight 1” pitch VPX boards) into a compact 10”x12”x14” conduction-cooled chassis weighing less than 40 pounds. This example rugged GP-GPU HPEC system can deliver 4 Teraflops of SWaP-optimized processing capability to the most challenging platforms requiring SAR. The VPX6-490 runs NVIDIA’s CUDA libraries unchanged. After multiple years under the open source community’s optimizations, the CUDA libraries have made SAR algorithm requirements easier to implement. Therefore, multi-core GP-GPUs for algorithm processing on UAV SAR systems are set to go higher and faster than ever before.







