
Accelerating floating-point designs on FPGAs using math.h functions
StoryAugust 26, 2010

Michael Kreeger
Kreeger Research
Brian Durwood
Impulse Accelerated
Floating-point math is increasingly necessary for 10/10ths accuracy in high-performance computing. Because hardware resources are not infinite for most of us, an understanding of practical approaches such as using math.h library functions for floating-point designs on FPGAs becomes integral.
Because of their flexibility advantages, FPGAs hold great promise for in-line hardware acceleration of processes that benefit from floating point. As such, FPGAs are finding their way into computational finance, scientific computing, and government and military applications.
FPGA adoption in floating-point design has been impeded by 1) issues with ease of use; 2) the need to write VHDL interfaces for C functions; and 3) inability or limitations in using known-good code. However, a new floating-point FPGA library is accelerating FPGA-based algorithm development. This library and tool flow is particularly beneficial for software developers experimenting with FPGAs for hardware acceleration of their code. The enabling elements are the emergence of robust tools for moving C to the FPGA without having to be a hardware guru, and most recently, flexible math.h libraries for common integer and floating-point computations.
Collectively the newer approach of using a math.h library to floating point on FPGAs has the advantages of:
1. Recycling known-good code to reduce user coding errors.
2. Automating pipelining and synchronization issues.
3. Shortening algorithm iteration by up to 8x over HDL development – a case study is presented.
Reusing known-good code
Higher-level math is used to calculate functions enabling machine vision to track moving objects, such as threat identification systems being developed for fighter jets. Engineers need trigonometry to figure out distances to objects, angles of view, perspectives, and relative positions. In algorithms like these, in which moving objects are tracked, vector math is heavily used. These problems have been often solved in microprocessor or DSP software code, resulting in significant power and space demands. To execute algorithms reliably in hardware, using tested hardware equivalents of floating-point functions is much safer than creating new ones.
Hence, using known-good math.h library functions reduces errors that can, by the geometric nature of the moving targets, amplify small mistakes beyond tolerance. Ironically, this is also true in long-range financial options calculations. There was an instance in European options a few years ago, where a small math imprecision created hundreds of thousands of dollars of errors when extended out 18 months, for which the bank was liable.
Until fairly recently, FPGAs were less common as devices for floating-point implementation. A leading engineer at an FPGA manufacturer pointed out that it can be difficult to predict the dynamic range of a digital signal processing system and implement a fixed point system to match. Given that FPGA sizes continue to increase, while logic costs continue to decrease, it is reasonable to assume that signal processing functions will migrate away from fixed point arithmetic and move towards floating-point arithmetic. Basically, that’s a nice way to explain that cheap gates will make FPGA-based floating point less of a luxury.
Parallelism eases pipelining, synchronization
Supercomputer architectures are taking an interesting shift towards slower clock speed, massively parallel arrays. Logic optimized for these architectures relies on a shift to individual processes that are synchronized via methods such as shared memories. This parallelism can be implemented in terms of spatial or temporal shifting (Figure 1). Logic challenges with significant non-sequential processes are good candidates for this type of FPGA-enabled implementation. Within this category, floating-point designs can be challenging to implement and optimize in an FPGA.
Figure 1: Parallelism occurs in either a spatial or temporal methodology.
(Click graphic to zoom by 1.4x)
|
|
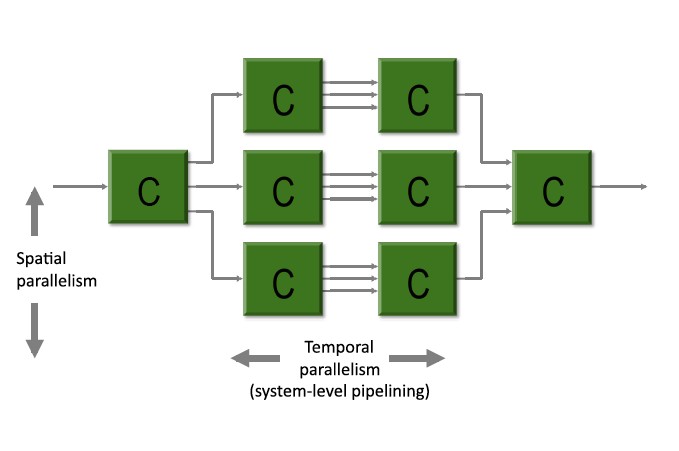
First, the typical floating-point design is optimized for a single- or dual-streaming microprocessor or DSP. FPGAs achieve performance through slower clock speeds, lower power, and massive parallelism, such as those featured in the early parallel processor array in Figure 2. (The figure depicts an early “desktop grid computer” developed by Assistant Professor Ross Snider and his students at Montana State University, who experimented with parallelism for neurological emulation in a 27-FPGA array using low-cost COTS devices[1].) Intrinsically, designs need to be refactored to run in parallel. This shift to “coarse-grained” streaming parallelism is not rocket science but is needed for the range of optimizing C compilers that work with FPGAs to unroll and parallelize the files to run in FPGAs. Deployment of math.h functions fits within this coarse-grained architecture methodology, which enables the algorithms to be machine optimized for parallel operation.
Figure 2: Early “desktop grid computer” developed by Assistant Professor Ross Snider and his students at Montana State University, part of an experiment with parallelism as part of a shift to “coarse-grained” streaming. Deployment of math.h functions fits within this coarse-grained architecture methodology.
|
|

Case study: Algorithm iteration 8x faster than HDL
In a step towards making FPGA algorithms even more predictable, the preconfigured math.h library can be used to accelerate FPGA-based algorithm development and extend math operations. ANSI C-compatible tool sets can work in front of synthesis tools from Xilinx, Altera, Synopsys, Mentor Graphics, and others.
The math.h library components are provided with standard C-language function prototypes, allowing them to be invoked from C, using common function-calling methods. For instance, for functions like y = atan(x), in VHDL the developer would have to write interfaces, entities, and more versus describing the algorithm in C and having the math.h library’s optimizing C compiler generate the VHDL. The VHDL is then either used just as VHDL, or is synthesizable into multiple brands of FPGA. This technique can reduce initial design time by about 1/3 and iteration time by 7/8ths.
The math.h library’s composition
The math.h library is provided as a set of HDL files and related configuration files implementing common mathematical operations. The currently available functions (more are being added) include: sin, cos, tan, exp, log, log10, pow, asin, acos, atan, sqrt, and fabs. Most of these functions involve the use of floating-point numbers, either single- or double-precision.
Unlike math.h functions that run “native” in embedded processors, this library is implemented directly in FPGA hardware, and supports refactoring into multiple, pipelined parallel processes. When used in this way, the math.h functions operate 2 to 10x faster than on embedded processors. The math.h library adds more scientific, algorithmic, and engineering functions to the existing C to FPGA floating-point support. These C-callable functions represent optimized math elements that are instantiated, through the use of synthesis and place-and-route tools, in the target FPGA. Running floating-point functions directly in hardware helps accelerate the performance of embedded applications.
In the “why bother” category, let’s look at the “before and after” of a common function. As implemented without invoking a library function (that is, the “before”):
library ieee;
use ieee.std_logic_1164.all;
library impulse;
use impulse.components.all;
use impulse.xilinx_float_math_fast.all;
use impulse.xilinx_float_fast.all;
entity dut is
port (signal reset : in std_ulogic;
signal sclk : in std_ulogic;
signal clk : in std_ulogic;
signal y_out_rdy : in std_ulogic;
signal y_out_data : out std_ulogic_vector (31 downto 0));
end dut;
architecture rtl of dut is
signal val_x : std_ulogic_vector (31 downto 0);
signal val_y : std_ulogic_vector (31 downto 0);
begin
val_x <= X”0x4039999a” -- represents a float value of 2.9
logf_fast_0: logf_fast
port map (
clk => clk,
a => val_x,
go => ‘1’,
result => y_out_rdy,
pipeEn => y_out_rdy);
end rtl;
As implemented with a known good math.h library, it’s a bit shorter to say the least (aka, the “after”):
#include
void main(void) {
float x,y;
x = 2.9;
y = logf(x);
printf(“result=%f\n”,y);
}
The typical design flow is vastly streamlined:
1. Combine math.h library function calls C-language to create complex systems.
2. Integrate pre-optimized library blocks from FPGA manufacturer libraries.
3. Analyze, refactor, compile, and iterate to optimize FPGA performance.
4. Verify C code functionally in a desktop environment such as Visual Studio, Eclipse, and GCC-based tools.
5. Export synthesizable VHDL or Verilog to FPGA synthesis and platform tools.
Within the math.h library toolset, support for module generation allows hardware IP blocks to be generated from the C language, using named ports and streaming API functions to integrate these blocks with the overall design. IP blocks can be mixed with Verilog or VHDL or with IP created using FPGA manufacturers’ tools. For video applications, the C API functions can be used to combine multiple streaming C-language processes to create highly pipelined, high-throughput systems (see Figure 3). Math.h operators are easily called within this tool flow, providing parallelized, optimized versions of math.h elements that integrate seamlessly into Impulse CoDeveloper Version 3.
Figure 3 (top screen), shows the VisualStudio rendition of the original C code with some refactoring into multiple streams. The pop-up flow window is a graphic interface that can be used to profile code by showing where bottlenecks result: where there is potential for acceleration via refactoring that code block into more streams. For more detailed refinement, the same code feeds into an integrated stage-delay analysis tool (the tree-type diagram), which shows the propagation in maximum detail.
Figure 3: A depiction of the compact C-code design description, rendered in Microsoft Visual Studio, refactored into machine synthesizable VHDL. (top screen). The pop-up flow window is a graphic interface that can be used to profile code by showing where bottlenecks result.
(Click graphic to zoom by 1.9x)
|
|

Math.h library eases FPGA development pain
For software developers exploring hardware acceleration, automating floating-point library acceleration lowers a hurdle for software-to-hardware compilation. Within the realm of Impulse Accelerated Technologies’ Impulse tools, software developers are able to refactor C code for massive parallelizing to exploit available FPGA resources. It is our experience that FPGAs are moving more into high-performance computing and, as such, will become the pre- or co-processing element in a design responsible for the heavy lifting on non-standard logic constructs.
Michael Kreeger is Principal at Kreeger Research, where he designs high-performance, communications, and math-oriented FPGA-based libraries for government, industrial, and wireless development teams. He graduated with a BSEE Cum Laude from the University of Massachusetts. He can be contacted at mike@kreegerresearch.com.
Brian Durwood founded Impulse Accelerated Technologies with David Pellerin in 2002 to provide C-to-FPGA based tools, training, and IP. He was a VP at Tektronix’s high-frequency MCM division in the ’90s, an original member of the ABEL team in the ’80s, and is a Business graduate of Brown University. He also received an MBA from University of Pennsylvania’s Wharton School of Finance. He can be contacted at brian.durwood@ImpulseC.com.
Impulse Accelerated Technologies 425-605-9543 www.impulseaccelerated.com
References:
- Developing a Data Driven System for Computational Neuroscience, by Ross Snider and Yongming Zhu, Springer Berlin/Heidelberg, http://www.springerlink.com/content/ejc270741d7cmn6n/






